Dear Author(s):
Congratulations on your conditional acceptance for publication.
I am the Data Editor for Economic Inquiry, and in this letter, I provide some basic guidance as you prepare your replication package. The instructions for how to start and publish on openICPSR are already posted on the website. Please read them carefully and follow them. Here instead, I draw your attention to a few important points that the Data Team at EI will check for the completeness of your archive. Note that an archive should be uploaded even if the data is confidential or proprietary and cannot be shared in the archive. I also provide some guidance on that at the end of this letter.
- Documentation/README file. You must provide full documentation of your replication archive via a README file. Please organize the information about your archive using the README file template provided by the social science editors. We have moved to using this template for all papers and a copy is available from https://social-science-data-editors.github.io/template_README/. As you will see it will prompt you about data sources, location of data and code in the archive, software versions, system requirements, run time, and statements about rights and data provenance among other useful information that should be included in a README file.
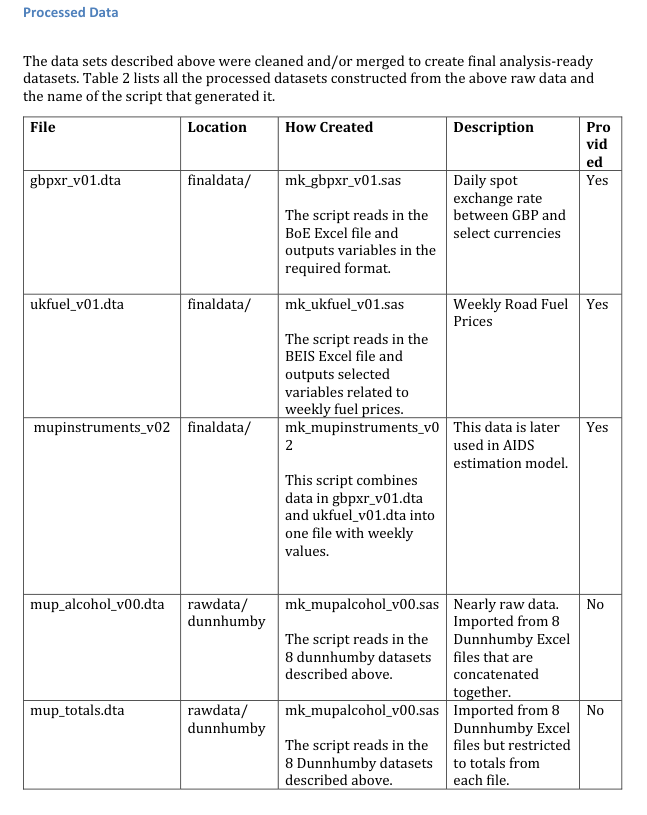
- Raw data. Please don’t submit just the processed analysis-ready datasets and the code to generate results from this data. We require (1) detailed information about data sources, (2) copies of all the raw data, (3) code to clean/process the raw data into analysis-ready datasets, and (4) where applicable, script to collect the raw data (e.g., web scraping, experiments, and surveys).
-
- For data sources, please provide detailed information so another researcher can obtain the same data. If it is a freely available dataset from a public website, include the precise URL to the data files or series name. For example, if the data is from the World Bank, it is not sufficient to just say it was from there and provide the web address of WB. Instead, provide the exact data base and series name and/or precise URL from where it was downloaded. Similarly, if they are menu-driven websites/interfaces, then again provide some guidance on how to interact with the website.
-
- If the data is proprietary or administrative, then regardless of whether the data can be shared in the archive or not, it is important that contact information be included so that an independent researcher can write to request access to the same files. In addition to the contact information, please also list the exact names of data files that you initially obtained. If instead the data was obtained by interacting via a proprietary software/portal/ or some similar interface, it may be helpful to create a separate instructional file (e.g., a README_appendix) that explains the steps in detail. This could include screenshots or specific instructions on how to search for and download the relevant data.
-
- If the data was collected via web scraping, online surveys, or lab/field experiments, please provide details on platforms, software, versions, and copies of your script and raw data. For example, if you used Qualtrics for a survey, include copies of QSF files, the exported raw data (CSV or Excel files usually but minus any identifying information such as email addresses or IP addresses), and some screenshots. If it was scraped, provide copies of the scraping code plus any files that you downloaded, e.g. HTML files or CSV files in which you directly imported the data (if it is lots of HTML files, put them in a separate folder). Similarly, if you used o-Tree or z-Tree, provide the code in a separate folder as well as some screenshots and raw data as exported from the software. We typically aim to execute this code up to the point where we can see the initial splash screen as seen by the participants.
-
- If your paper mainly uses calibrations and/or simulations, you must provide a code for that. Two things to keep in mind when submitting your package. (1) If the same script is to be used to generate different results by changing a series of parameter values in the same code, then either these must be described very carefully in the README so that the replicator can follow, or preferably, create a master file that repeatedly calls up the script and passes it the correct combination of the parameter values, or you can create copies of the code for each result and preset the values. (2) If the parameter values are set based on earlier literature, please include in the README a table of values and citations. But if the parameter values are based on your calculations from various data sources, then the previous instructions for empirical papers about raw data and code to clean and generate those results also apply to the papers with calibration exercises.
-
- Finally, for all of the cases above, provide code that constructs your final analysis-ready data set along with any instructions on how to execute the code (for instance, the order in which the code is to be executed).
- Processed data and code to generate the results. In addition to the raw data and code mentioned above, if your code generates intermediate or final analysis-ready data sets, and then an additional script is used to generate the results, please provide copies of all these files and clearly describe them in the README. See the next point below.
- Data and code tables. Organize details about all raw data files in a table, including entries for data files withheld due to confidentiality or redistribution restrictions. Any other essential details can be included in the notes below the table. Additionally, create a separate table listing all processed datasets and indicating which scripts generated them. The distinction between raw and processed data should be clear. Examples of these tables are provided at the end of this letter, and further examples can be found in the README template.
- Mapping outputs. Please ensure that the output from the code (tables, figures, etc.) can be easily mapped to the results in the paper. Annotations in the script, easily identifiable names of script or outputs (e.g. table01.do or table01.txt) or again use of a mapping table in the README can facilitate this process.
If the data is proprietary, administrative, or confidential and cannot be included in the archive, or none of these but redistribution is not allowed, then exemptions are available. In these cases, please clearly list the reason in the README for not including the data. Where possible, we may ask that the confidential information be removed, and the rest of the data be shared. Alternatively, you may consider providing synthetic data to the archive for code checking. These will be dealt with on a case-by-case basis.
Two final thoughts. First, after you have prepared and uploaded your archive to the openICPSR, test it by downloading it to another computer/system that was not used during your original research. Do this before you click on the ‘PUBLISH’ button on the project page on openICPSR. The reason is that the archive often works on the authors’ computers, but not on independent computers either due to special installed packages or paths set on the local computer that load up some script or data that has not been included in the archive. Other times, paths to various files are hard coded rather than being relative links and so the code keeps failing on other computers. Second, use the checklist provided on the website to check your archive. My Data Team members use this to identify any gaps in the archive and if you have already checked against it before submitting and made any necessary corrections, this will speed up the process of approving your archive and converting your conditional acceptance to final acceptance by the co-editor in charge of your paper.
Good luck with preparing your archive. And feel free to reach out to me if you have any questions.
Kind regards,
Farasat Bokhari
Co-editor & Data Editor, Economic Inquiry
Professor, Loughborough Business School,
Loughborough University, and
Centre for Competition Policy (UEA)
Figure 1
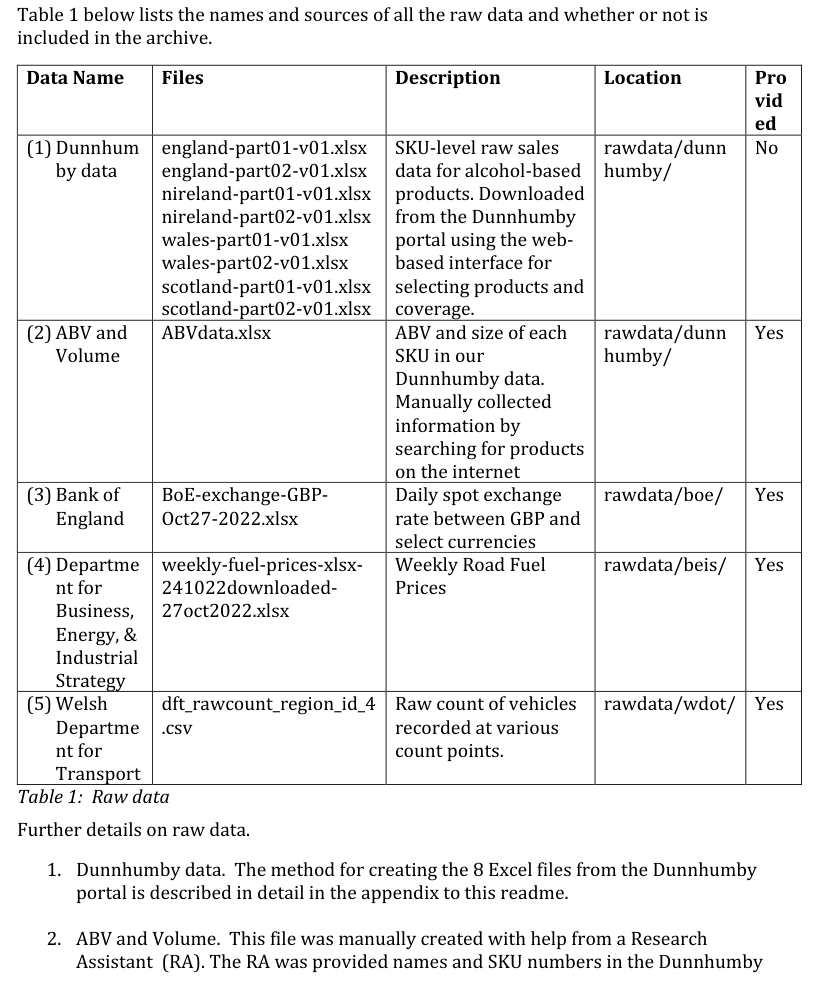
Figure 2.